Alert rules 설정
이전 글에서는 디스코드 웹 훅을 만들고 그라파나와 연동을 해보았다.
이번 글에서는 그라파나에서 Alert rules에 장애 조건을 설정하고,
장애 발생 시 연동한 디스코드로 경고 메시지를 보내는 설정을 해볼것이다.
구현하기
이번 글에서는 간단히 특정 상황 발생 시 디스코드로 경고 메시지를 발송하는 정도로 구현할 것이다.
기본적으로 그라파나는 프로메테우스 서버에서 받은 데이터를 이용하므로 프로메테우스 서버는 항상 켜져있어야 한다.
순서는 아래와 같다.
- 그라파나의 Alert rules 설정
- 결과 확인
1. 그라파나의 Alert rules 설정
다음은 그라파나에서 경고 메시지를 보낼 조건을 설정한다.
우리의 그라파나 서버는 프로메테우스에서 받은 데이터를 토대로 하므로 애플리케이션 상태에 따른 조건을 설정할 수 있다.
프로메테우스 설정을 원하는대로 설정하여 여러 애플리케이션 서버나 DB 서버의 알림 설정을 할 수 있다.
본인은 prometheus.yml 파일을 간단히 아래처럼 설정하였다.
# prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# Here it's Prometheus itself.
scrape_configs:
- job_name: "spring-actuator"
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: [ 'localhost:8080' ]
Alerting 탭에서 Alert rules 페이지로 이동하여 새로운 규칙을 추가한다.

1-1. 규칙 이름
규칙 이름을 설정한다.
1-2. 경고 메시지 발송 조건 설정
경고 메시지 발송 조건을 설정한다.
- 최상단의 Query 측에서 프로메테우스(혹은 다른 DataSource)에서 받은 데이터로 쿼리를 작성할 수 있다.
- 아래쪽 Expressions로 Query 결과를 이용한 표현식을 통해 조건을 설정할 수 있다.
필요하다면 Query, Expressions를 추가할 수도 있다.
본인은 Query 결과를 이용하여 Expressions에서 조건을 설정해보았다.
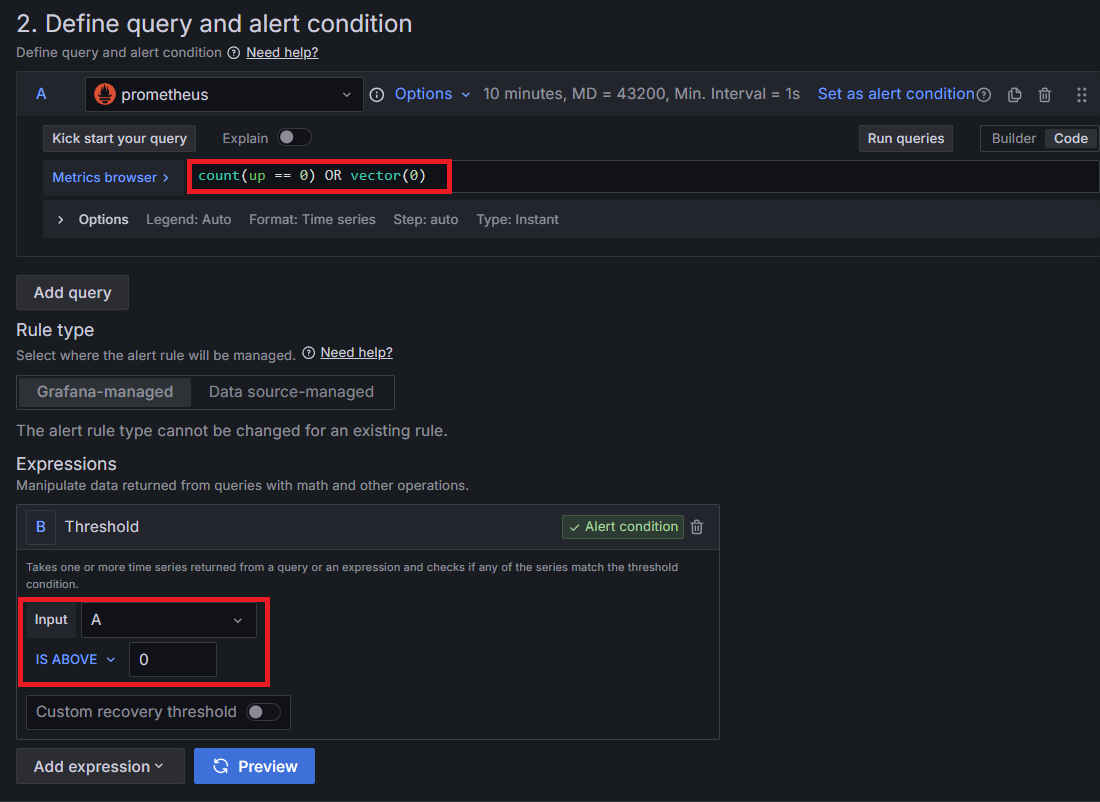
아래 사진의 promQL은 내려가있는 인스턴스가 있는지 확인하는 쿼리이다.
여기서 up은 인스턴스의 활성화 여부이며, 0은 비활성화 상태이고 1은 활성화된 상태임을 뜻한다.
count는 괄호 안의 조건에 맞는 결과의 갯수를 반환한다.
count(up == 0)에서 비활성화 된 인스턴스가 없으면 no data를 반환하므로 OR vector(0) 을 추가하여 0을 반환하도록 한다.
쿼리 값(A 값)이 0보다 크면 경고 메시지를 발송하도록 설정하였다.
1-3. 서비스 상태 확인 간격 및 메시지 발송 시간 설정
Evaluation behavior은 서비스의 상태 확인에 관련된 세부 설정이다.
여기서 서비스 상태를 얼마 간격으로 다시 확인하는지, 장애 발견 후 얼마 뒤에 메시지를 발송할 지 설정한다.
본인은 아래처럼 설정하였다.
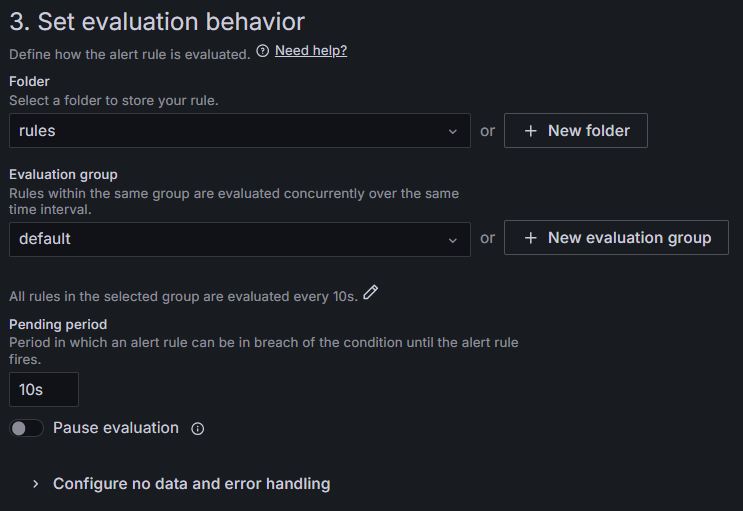
ㄴFolder
디렉토리를 설정할 수 있다.
본인은 rules 라는 디렉토리를 만들었다.
ㄴEvaluation group
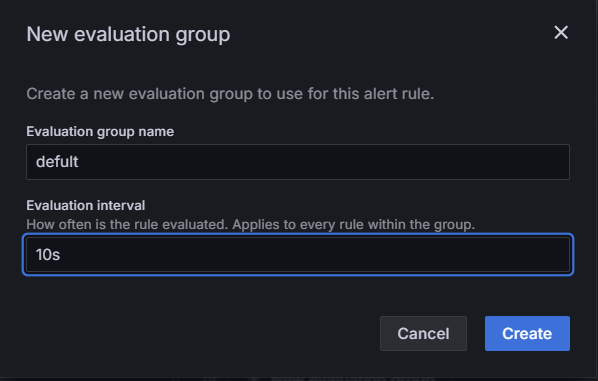
Evaluation group에서 해당 그룹은 얼마 간격으로 서비스 상태를 다시 확인하는지 설정할 수 있다.
본인은 테스트의 용이성을 위해 아래처럼 10초 간격으로 상태를 다시 확인하는 그룹을 만들고 설정하였다.
ㄴPending peorid
Pending peorid에서 장애 발생 후 얼마 뒤에 메시지를 보낼지 설정한다.
이 또한 테스트 용이성을 위해 10초 간격으로 설정하였다.
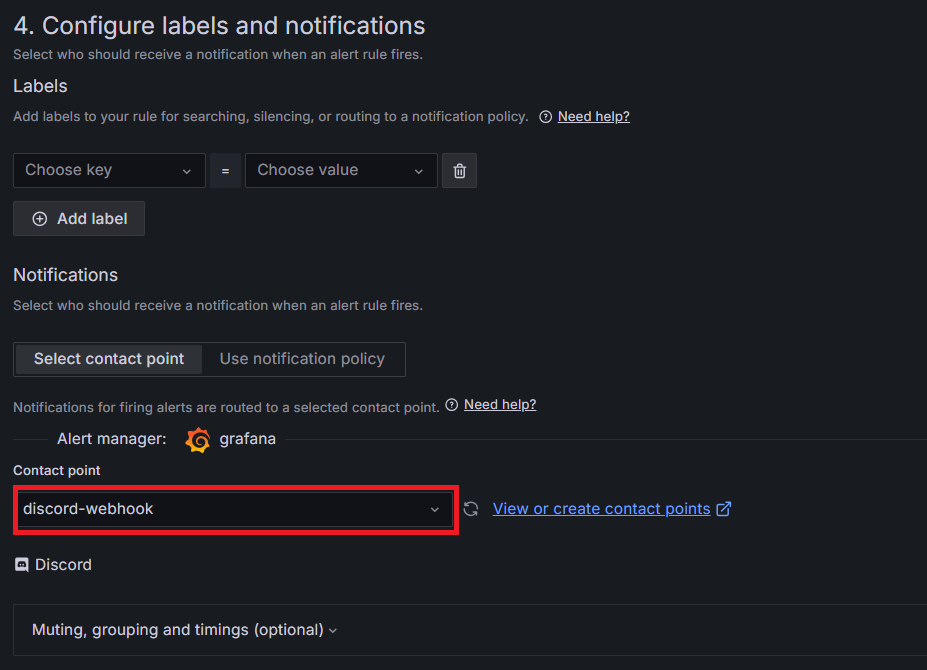
1-4. 장애 발생 시 메시지를 전송할 경로 설정
연동한 디스코드 웹 훅 경로로 메시지를 보내도록 Contact point를 지정한다.
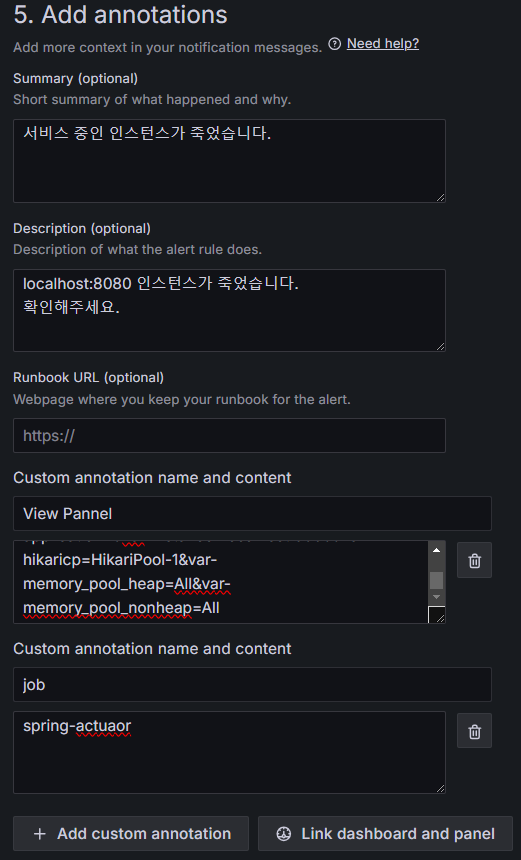
1-5. 경고 메시지 내용 설정
아래처럼 경고 메시지 내용을 설정할 수 있다.
Add custom annotation 으로 원하는 내용을 추가할 수도 있다.
본인은 job 이름과 스프링부트 애플리케이션 상태를 확인할 수 있는 패널 경로를 넣어주었다.
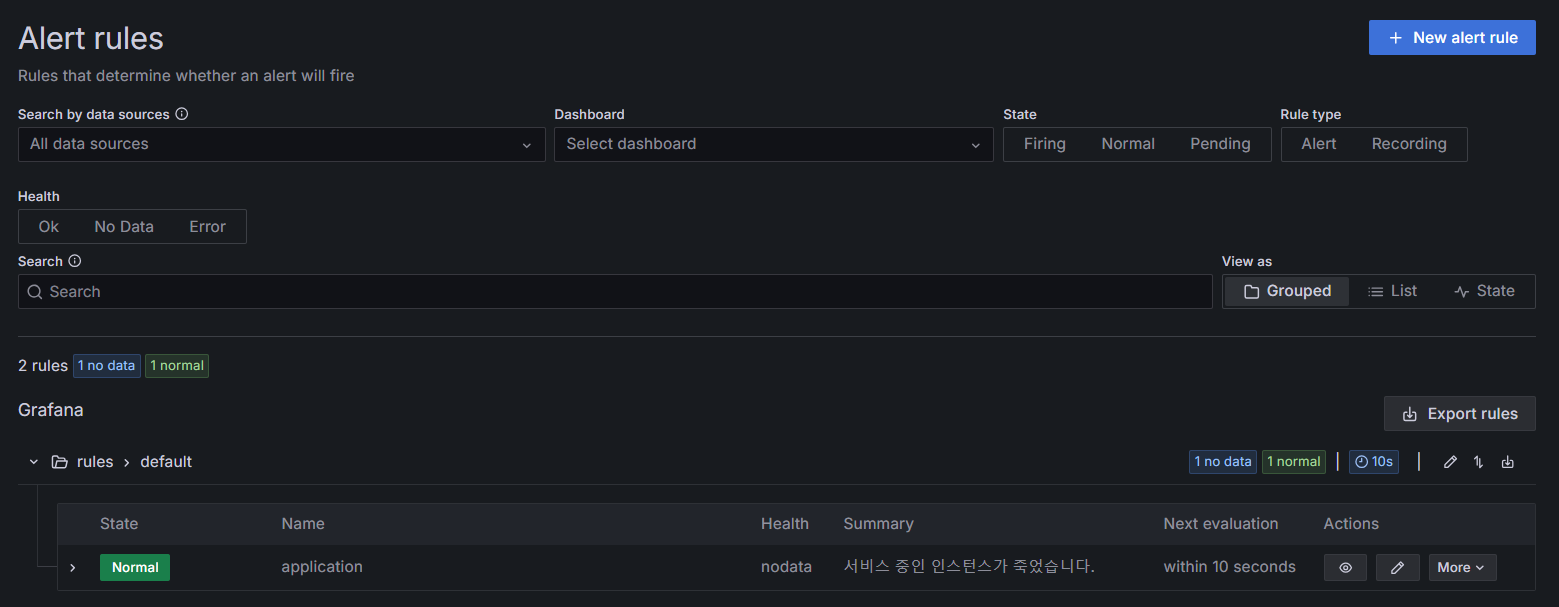
여기까지 설정 했으면 우상단의 저장 버튼을 누르면 Alert rule이 추가되고, 아래처럼 추가된 Alert rule을 확인할 수 있다.
2. 결과 확인
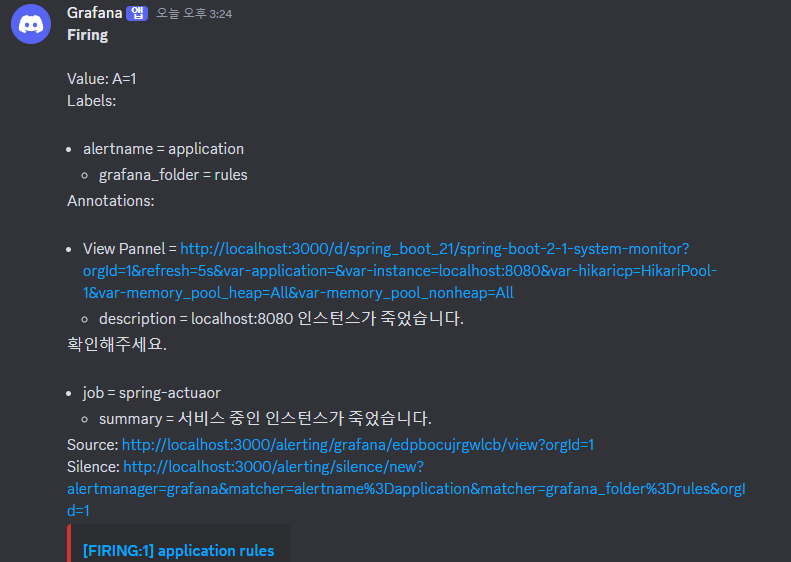
알림 설정이 제대로 동작하는지 확인해보기 위해 애플리케이션을 종료해보았다.
아래처럼 디스코드로 설정한 경고 메시지가 잘 전달됨을 확인할 수 있다.
참고자료
[과제] prometheus와 grafana를 이용한 MySQL 모니터링 구축
prometheus와 grafana를 이용한 DB 모니터링 구축하기서버 1: DB 서버DB 설치프로메테우스 exporter 설치 (node exporter, db exporter)서버 2: 모니터링용 서버프로메테우스 설치그라파나 설치서버 1에는 2개 이상
velog.io
Grafana Alert 적용하기
Grafana를 프로젝트에 적용하고 모니터링을 완성한 후 장애가 발생했을 때 email로 받아보면 좋겠다는 생각을 하게 되었습니다. Grafana Alert 기능을 사용하면 장애 발생 시 email로 받아볼 수 있음을
velog.io
'백엔드 > 연습' 카테고리의 다른 글
| 애플리케이션 로그를 파일로 저장하기 (0) | 2024.06.18 |
|---|---|
| 서비스 장애 알림 1: Grafana와 Discord 연동 (0) | 2024.06.15 |
| Grafana로 애플리케이션 상태 확인해보기 (0) | 2024.06.08 |
| Grafana를 이용하여 메트릭 시각화 (0) | 2024.06.07 |
| Prometheus를 이용하여 메트릭 수집 (0) | 2024.06.06 |










