인덱스
지금껏 DB를 Jpa로 접하고, 공부도 부족해서 DB에 대해 너무 모르고 있었다.
인덱스도 이름만 들어보고 사용하면 읽기 성능이 좋아진다 라고만 알고 있었지 직접 써보질 않았기 때문에 잘 와닿지는 않았다.
이번 기회에 MySQL을 공부하면서 인덱스를 사용해서 성능 비교도 해보면서 DB에 대한 이해를 넓혀보고자 한다.
사용 기술
- MySQL 8.4
- DBeaver
사전 작업
아래처럼 DB에 400만 건의 데이터를 넣어뒀다.

데이터 형식은 아래 사진과 같다.
memberId = 1에 해당하는 데이터는 300만건, memberId = 2에 해당하는 데이터는 100만건이다.
- 날짜는 5월 26~ 27일 사이의 랜덤 값
- memberId = 1 또는 2이다.
- content는 랜덤한 값

이 데이터들을 이용하여 인덱스 사용 전/후의 성능을 비교해볼 것이다.
1. 인덱스 사용 전
인덱스를 사용했을때와 비교해보기 위해 대조군으로 측정한다.
1-1. 실행 계획 분석
MySQL의 EXPLAIN 을 이용하여 실행 계획을 분석한 결과는 아래와 같다.
인덱스 없이 탐색한 rows가 거의 400만 개로 풀 스캔한 결과인듯 하다.

1-2. 쿼리 시간
400만 건의 데이터를 조회하는데 18초가 걸렸다.

1-3. CPU 점유율
400만건의 데이터를 조회하기 위해 CPU 점유율이 27%까지 올라갔다.

2. 인덱스 추가
이제 인덱스를 추가해보자.
SQL로 생성해도 되고, DBeaver 같은 GUI를 써서 추가해줘도 된다.
본인은 아래처럼 GUI로 3개의 인덱스를 추가해줬다.
- createdDate 인덱스
- memberId 인덱스
- createdDate, memberId 복합 인덱스
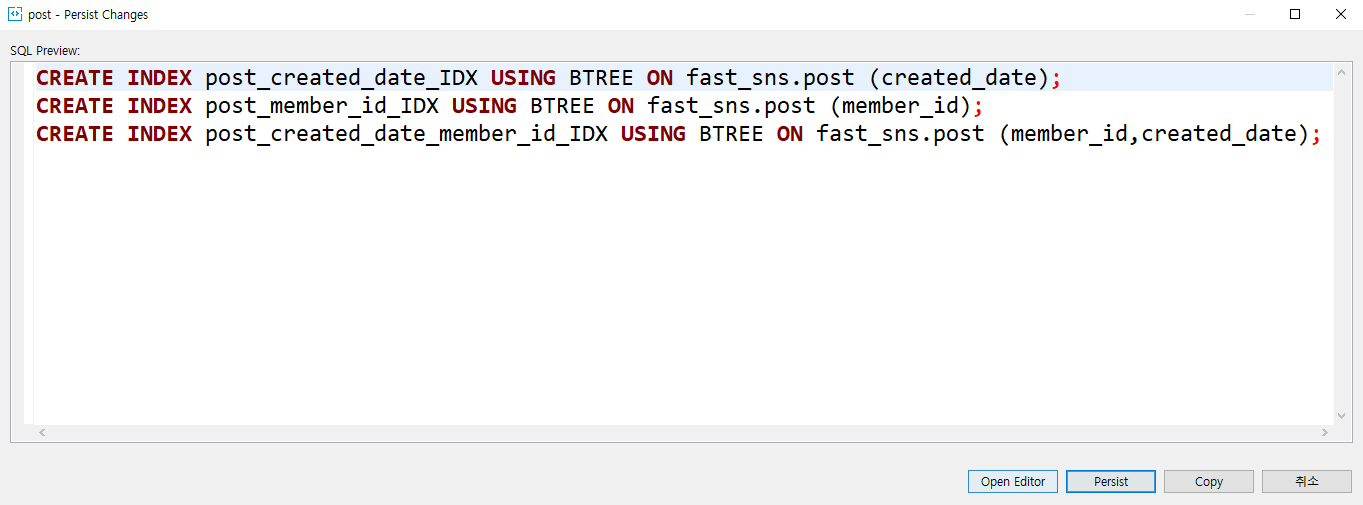
인덱스 생성 결과는 아래처럼 확인할 수 있다.
이 인덱스

3. memberId 인덱스 사용
3-1. 실행 계획 분석
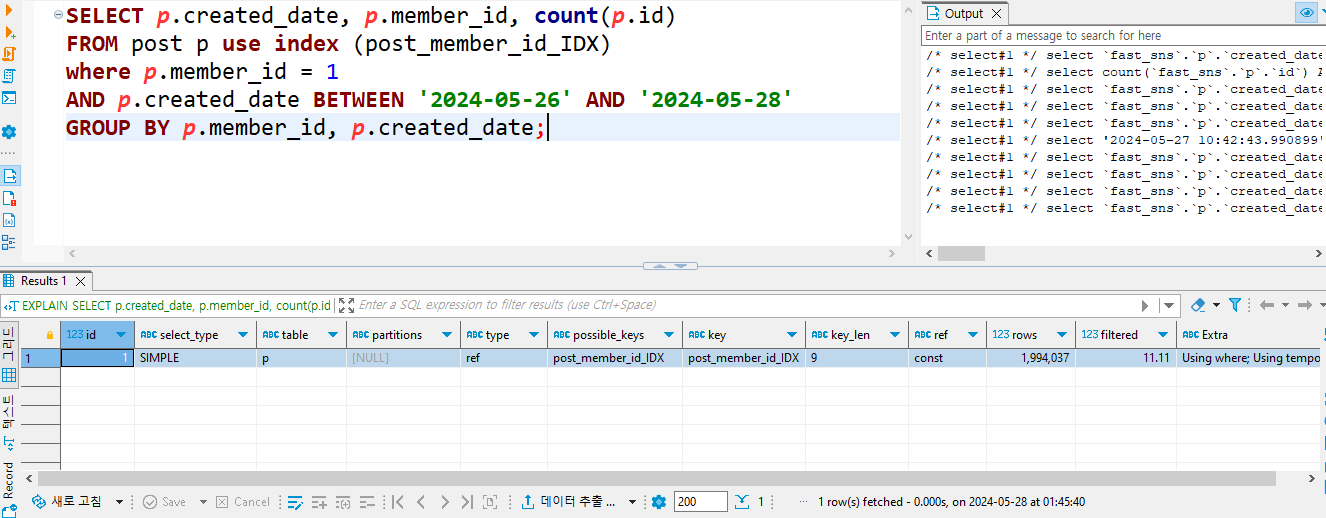
3-2. 쿼리 시간
24초로 인덱스를 타지 않은 쿼리보다 느린 결과를 얻었다.
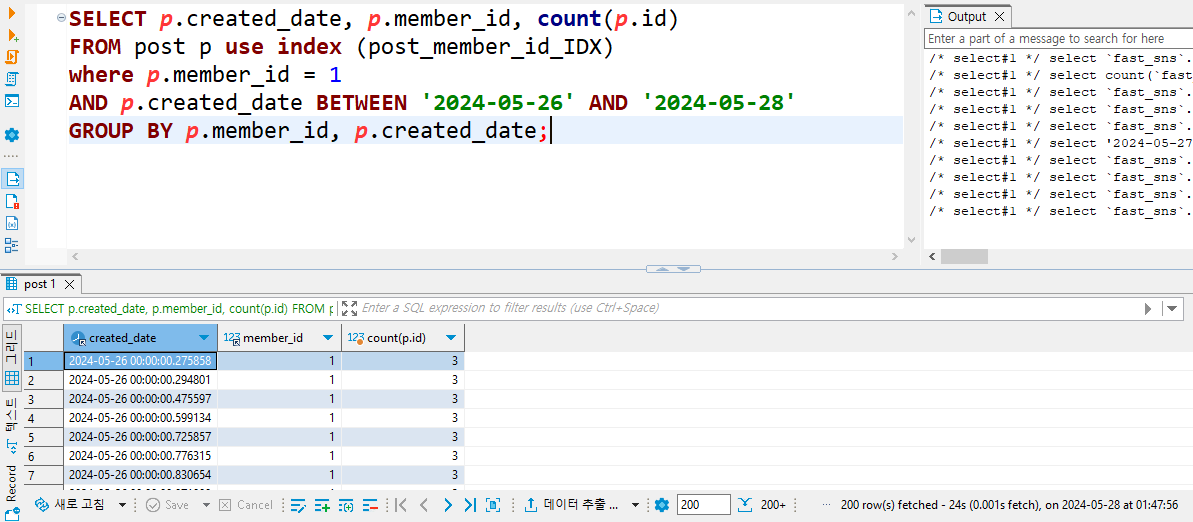
3-3. CPU 점유율
인덱스를 타지 않은 쿼리보다 더 높은 CPU 점유율을 기록했다.

3-4. 결과 분석
인덱스를 걸었음에도 불구하고 쿼리 시간이 더 느려졌다.
이유를 찾아보자면 인덱스를 탔음에도 탐색 범위를 많이 줄이지 못했기 때문에 인덱스 테이블도 확인하고,
Post 테이블의 데이터까지 확인해야 했기 때문에 인덱스 없이 테이블 풀 스캔을 한 결과보다 느리게 나왔다고 볼 수 있다.
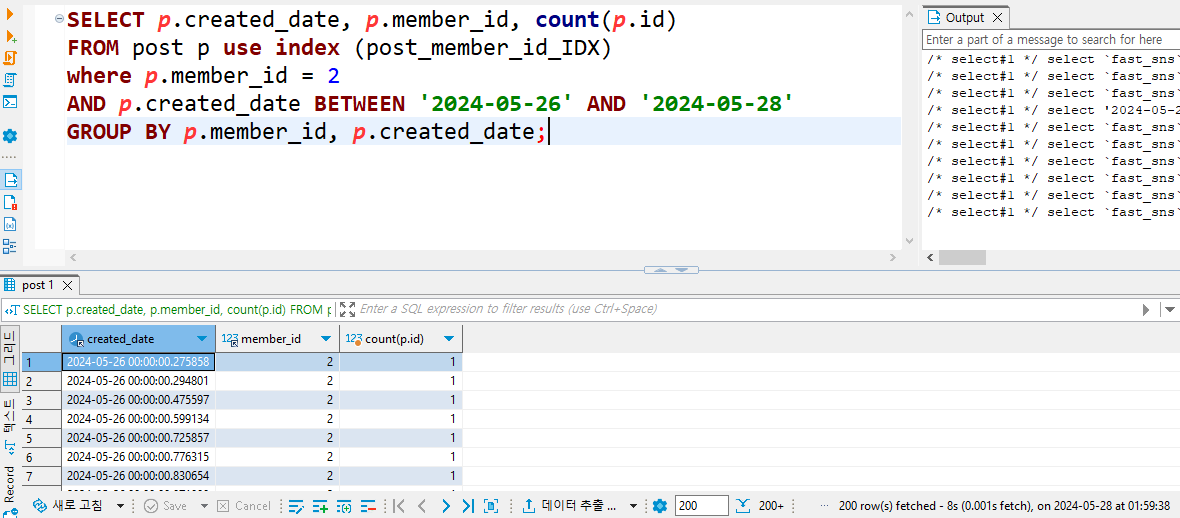
참고로 memberId = 2로 쿼리를 날려보면 아래처럼 쿼리 속도가 8초로 개선됐음을 확인할 수 있다.
이를 통해 쿼리에 해당하는 데이터 분포도에 따라서 쿼리 속도가 더 느려질 수 있다는걸 알았다.
4. createdDate 인덱스 사용
4-1. 실행 계획 분석
rows 만 보면 인덱스를 사용하지 않았을 때와 큰 차이가 없다.
하지만 type이 all 이냐, index에 따라 효율이 달라지는듯 하다.
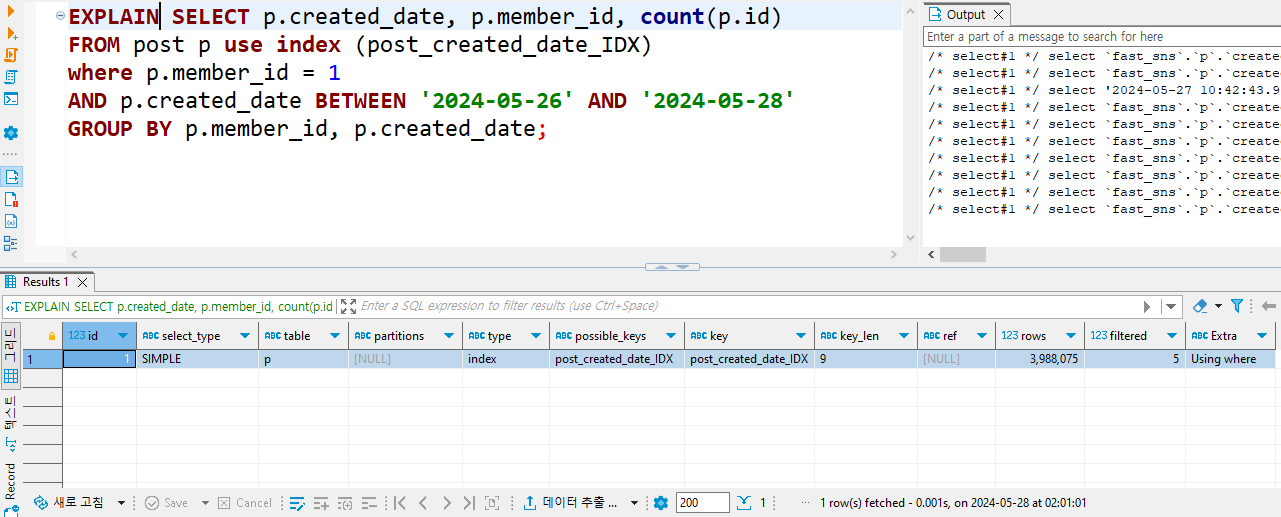
4-2. 쿼리 시간
인덱스를 타지 않은 쿼리보다 훨씬 빠른 조회 결과를 얻었다.
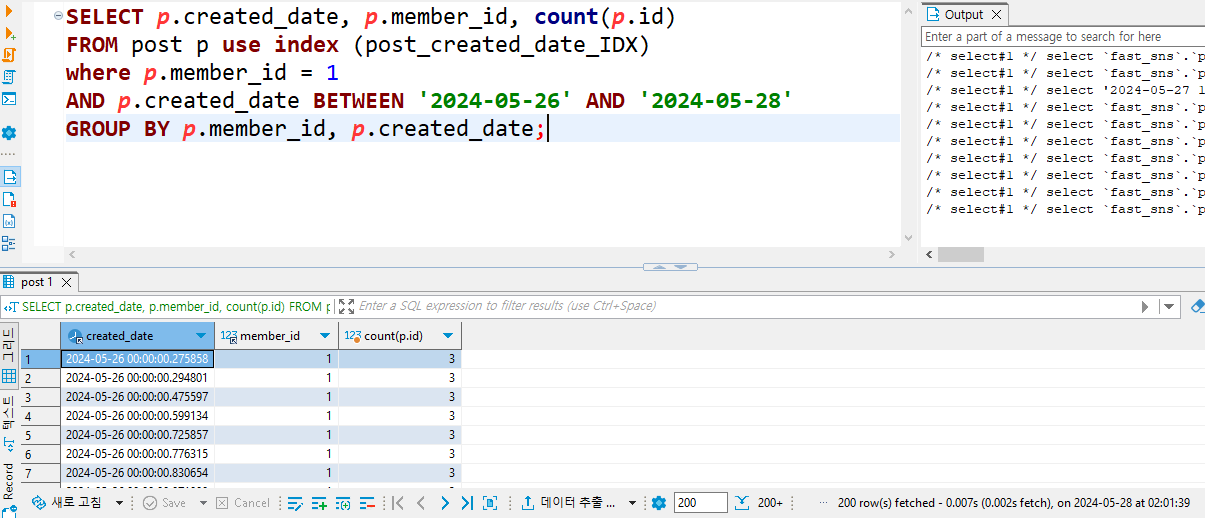
4-3. CPU 점유율
쿼리가 너무 빠르게 실행돼서 CPU 점유율 변동이 없었다.
거의 0.1% 정도라고 생각하면 될것 같다.
4-4. 결과 분석
createdDate는 데이터 분포가 골고루 되어 있어서 그런지 인덱스를 타면 조회 성능이 훨씬 개선됨을 알 수 있었다.
rows가 커서 조회 속도가 느리지 않을까 생각했는데 데이터 분포가 엄청 큰 영향을 미치는가 보다.
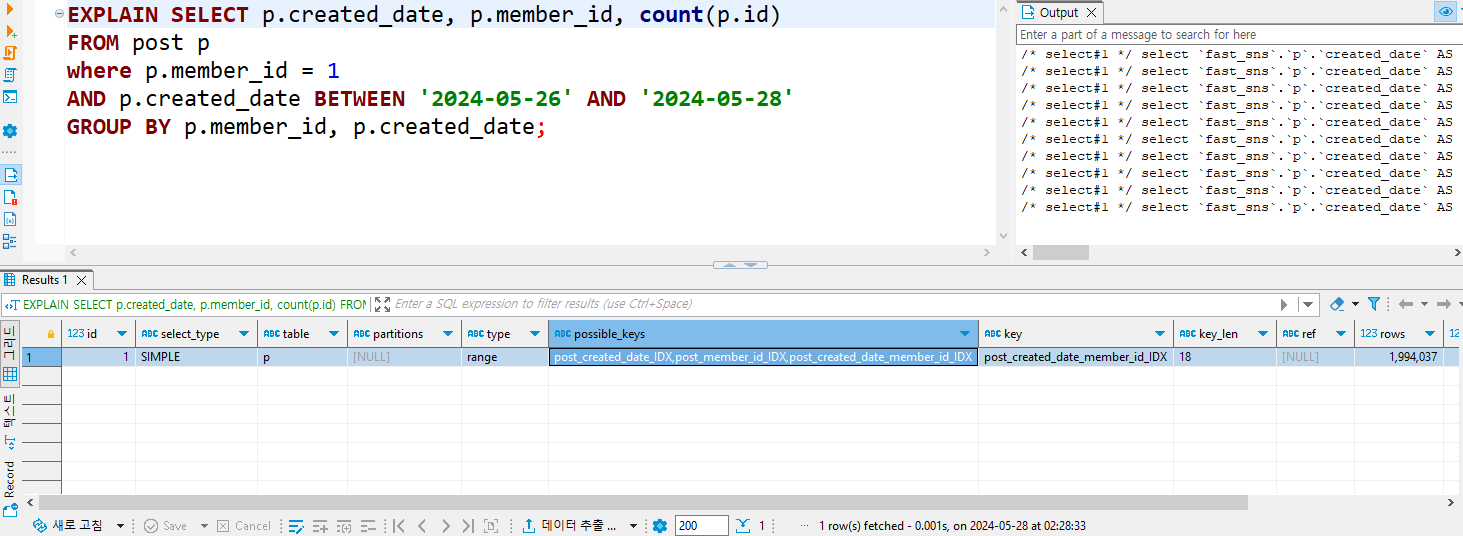
5. createdDate, memberId 복합 인덱스 사용
5-1. 실행 계획 분석
rows가 createdDate 단일 인덱스보다 더 적어졌다.
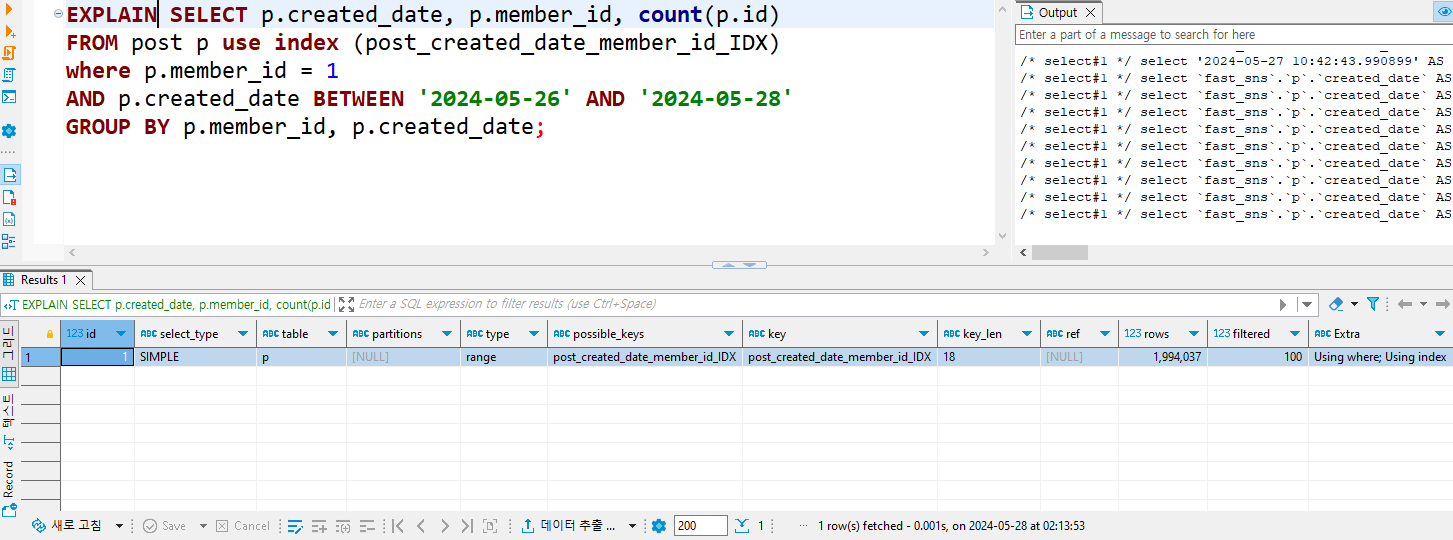
5-2. 쿼리 시간
createdDate 단일 인덱스 보다 더 빠른 조회 결과를 얻었다.
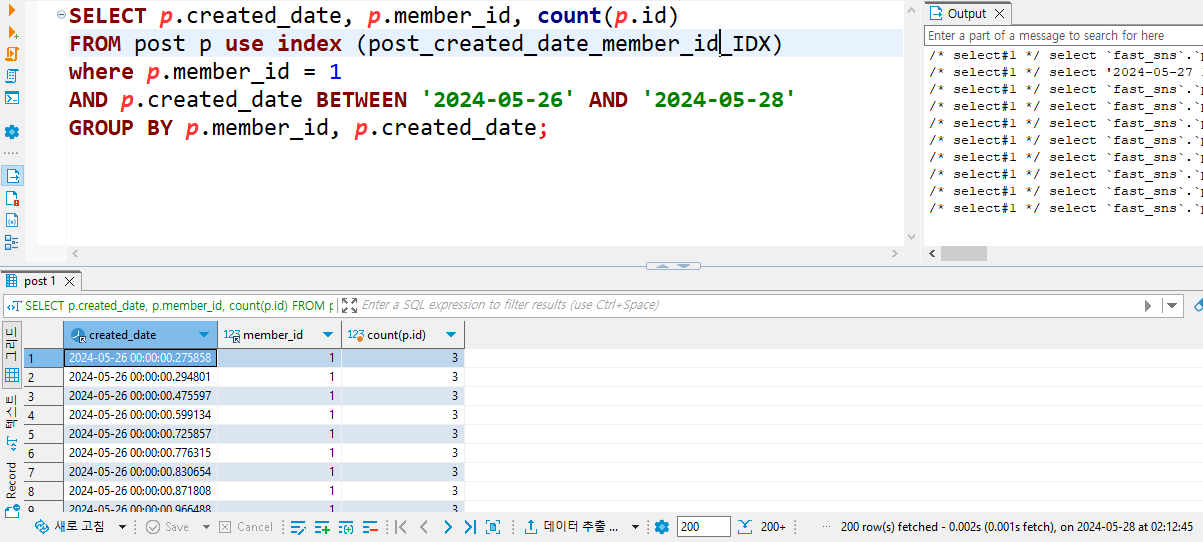
5-3. CPU 점유율
쿼리가 너무 빠르게 실행돼서 CPU 점유율 변동이 없었다.
여기서도 거의 0.1% 정도라고 생각하면 될것 같다.
5-4. 결과 분석
18초 걸리던 쿼리가 0.002초로 엄청난 조회 속도 개선이 되었다.
복합 인덱스를 잘 이용하면 단일 인덱스를 이용하는것 보다 더 좋은 조회 결과를 얻을 수 있는걸 알 수 있었다.
복합 인덱스는 인덱스 순서에도 영향을 받는다고 하니 잘 이용하기 위한 조건을 확인해서 잘 쓸 수 있도록 해야겠다.
6. 정리
특정 인덱스에 따라 성능이 좌우 되는건 아니고 데이터의 분포도에 따라 성능이 달라질 수 있음을 알았다.
인덱스를 사용하면 항상 성능이 좋아지는건 아니고 오히려 나빠질 수 있다는것도 알 수 있었다.
인덱스를 사용하기 위해 주의해야할 점과 더 효율적으로 쓸 수 있는 방법을 더 공부해봐야 할것 같다.
참고로 위에서 실험할때는 use index로 인덱스를 설정했다.
use index를 제거하면 아래처럼 MySQL 내부에서 최적화하여 인덱스를 타서 쿼리를 실행한다.
하지만 최적화 결과가 항상 최선은 아니기 때문에 EXPLAIN으로 자주 확인하는게 좋을듯 하다.
'데이터베이스' 카테고리의 다른 글
| Redis 써보기 (0) | 2024.04.17 |
|---|---|
| [DB] DML, DDL, DCL 이란? (0) | 2023.10.01 |





