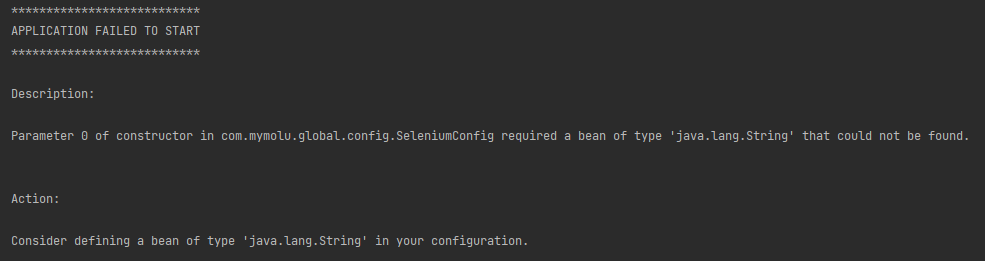
문제발생
이전 글에서 config 파일로 리소스 핸들러를 추가해 이미지 렌더링하는데에는 성공했다.
하지만 이전에 만들었던 SeleniumConfig 도 그런데, config 파일을 이렇게 사용하면 아래와 같은 문제가 있었다.
- 보안에 민감한 값을 포함할 수 있다.
- OS 별로 다른 변수를 이용해야할 수 있다.
문제해결
현재 프로젝트도 윈도우와 맥에서 사용하는 변수값이 달라서 고민이었고, 환경변수를 yml 파일로 분리하기로 했다.
방식은 이 글에서 썼던 @ConfigurationProperties 를 사용하는 방식을 채택했다.
과정을 요약하면 아래와 같다.
- yml 파일에 환경변수를 설정한다.
- @ConfigurationProperties 및 @ConstructorBinding 으로 yml 의 값을 바인딩한다.
- Application 클래스에 @EnableConfigurationProperties 로 해당 config 파일을 빈으로 활성화 한다.
1. yml 파일에 환경변수를 설정한다.
application.yml
selenium:
driver-name: "driver/chromedriver.exe"
// 윈도우 기준임. 맥은 driver/chromedriver
resource:
absolute-path: "file:///C:/Users/midcon/Desktop/my-molu-be/download/"
// 윈도우 기준임. 맥은 "Users/midcon/Desktop/my-molu-be/download/"
2. @ConfigurationProperties 으로 yml 의 값을 바인딩한다.
변경전
WebConfig
@RequiredArgsConstructor
@Configuration
public class WebConfig implements WebMvcConfigurer {
private final static String ABS = "\\C:\\Users\\midcon\\Desktop\\my-molu-be\\download\\";
private final CrawlingService crawlingService;
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
Path imageAbsolutePath = Paths.get(crawlingService.DOWNLOAD_DIRECTORY).toAbsolutePath();
// localhost:8080/images/image.jpg
registry.addResourceHandler("/download/**")
.addResourceLocations("file://" + ABS);
}
}SeleniumConfig
@Configuration
public class SeleniumConfig {
public ChromeDriver chromeDriver() {
System.setProperty("webdriver.chrome.driver", "chormedriver.exe");
ChromeOptions options = new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
ChromeDriver driver = new ChromeDriver(options);
driver.manage().timeouts().implicitlyWait(Duration.ofMinutes(3));
driver.manage().window().maximize();
return driver;
}
}
변경후
WebConfig
@RequiredArgsConstructor
@ConstructorBinding
@ConfigurationProperties(prefix = "resource")
public class WebConfig implements WebMvcConfigurer {
private final String absolutePath;
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
// localhost:8080/images/image.jpg
registry.addResourceHandler("/download/**")
.addResourceLocations(absolutePath);
}
}SeleniumConfig
@ConstructorBinding
@RequiredArgsConstructor
@ConfigurationProperties(prefix = "selenium")
public class SeleniumConfig {
private final String driverName;
public ChromeDriver chromeDriver() {
System.setProperty("webdriver.chrome.driver", driverName);
ChromeOptions options = new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
ChromeDriver driver = new ChromeDriver(options);
driver.manage().timeouts().implicitlyWait(Duration.ofMinutes(3));
driver.manage().window().maximize();
return driver;
}
}
3. @EnableConfigurationProperties 로 config 파일을 빈으로 등록한다.
MyMoluApplication
@EnableConfigurationProperties(value = {SeleniumConfig.class, WebConfig.class})
@SpringBootApplication
public class MyMoluApplication {
public static void main(String[] args) {
SpringApplication.run(MyMoluApplication.class, args);
}
}
이제 윈도우에서와 맥에서 yml 파일 설정만 바꿔주면 나머지 파일들은 모두 깃허브로 관리할 수 있다.
이전처럼 SeleniumConfig 파일을 .gitignore 에 등록할 필요가 없어졌으니 제거하면 된다.
이처럼 민감한 값이나 개발환경에 따라 다른 값을 사용해야할 경우 yml 파일로 환경변수를 관리하면 된다.
'나만의 몰루 사이트 > 트러블 슈팅' 카테고리의 다른 글
| [BE] 빌드 이후 이미지를 저장한 이미지를 렌더링하려 하면 엑박 (0) | 2023.12.13 |
|---|---|
| [BE] required a bean of type 'java.lang.String' that could not be found. (0) | 2023.12.10 |
| CORS 문제 해결 (0) | 2023.12.03 |
| [BE] 윈도우와 맥의 셀레니움 크롬드라이버 설정 차이로 인한 깃허브 관리 문제 해결(JAVA) (0) | 2023.11.20 |
| [BE] Mac 에서 셀레니움 사용 시 크롬 드라이버 실행 문제 (0) | 2023.11.15 |