Bulk Insert
최근 MySQL을 만져보면서 이런저런 DB 관련 공부를 하고 있다.
그러던 중 인덱스와 관련 해서 성능 테스트를 할 겸 DB에 여러 건의 데이터를 넣는 방법을 생각해보았다.
지금껏 여러 건의 데이터를 넣을 때는 대부분 SpringDataJpa의 saveAll()을 사용하였다.
애초에 아직까지는 해봐야 2자리 수나 100건 정도의 데이터 정도만 넣어보고 있었기에 별 불편함을 느끼지 않았다.
하지만 1만건 이상의 데이터를 넣어야 하는 일이 생길 수있으니 이번 기회에 여러 건의 데이터를 넣는 방법들에 대해 정리해보려 한다.
사용 기술
- Spring Boot 3.2.4 / gradle-kotlin
- Java 17
- MySQL 8.4
- EasyRandom, SpringDataJpa, JDBC
DB에 여러 건의 데이터를 넣는 방법
DB에 여러 건의 데이터를 넣는 방법은 이 글에 정리해두었다.
이 글에서는 위 글에서 정리한 방법들을 실습한다.
- JPA의 save() 사용 -> 데이터 수 만큼 for 문으로 Insert
- JPA의 saveAll() 사용
- JPA의 Bulk Insert 사용
- JDBC Bulk Insert 사용
공통적으로 이지랜덤이라는 라이브러리를 이용하여 1000개의 랜덤 객체를 만들어서 DB에 Insert 해보려 한다.
이제 각 방법들로 DB에 여러 건의 데이터를 넣어보고 비교 해보자.
1. JPA - save()
우선 Jpa의 save() 메서드를 이용한 테스트부터 해보자.
1-1. 코드
예시 코드는 아래와 같다.
SpringDataJpa를 사용하면 자주 썼을 JpaRepository의 save() 메서드를 for문으로 루프를 돌려보았다.
스프링 프레임워크 유틸에서 제공하는 StopWatch를 이용하여 객체 생성 시간과 DB Insert 시간을 측정하였다.
이지 랜덤을 이용하여 PostFixtureFactory를 만드는건 이전 글에서 사용한 방식을 이용한다.
BulkInsertTest
@DisplayName("")
@Test
void test() {
Long memberId = 1L;
EasyRandom easyRandom = PostFixtureFactory.get(
memberId,
LocalDate.of(2024, 5, 26),
LocalDate.of(2024, 5, 27)
);
// #1 - JPA save()
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<Post> posts = IntStream.range(0, 1000)
.mapToObj(i -> easyRandom.nextObject(Post.class))
.toList();
stopWatch.stop();
System.out.println("객체 생성 시간: " + stopWatch.getTotalTimeSeconds());
StopWatch queryStopWatch = new StopWatch();
queryStopWatch.start();
for (Post post : posts) {
postRepository.save(post);
}
queryStopWatch.stop();
System.out.println("DB Insert 시간: " + queryStopWatch.getTotalTimeSeconds());
}1-2. 결과
1000개의 랜덤 객체를 생성하는데는 0.11초밖에 걸리지 않는다.
하지만 DB에 데이터를 넣는데 11.45초가 걸린다.
1000번의 트랜잭션과 1000번의 Insert 쿼리가 시간을 많이 잡아먹는듯 하다.


2. JPA - saveAll()
2-1. 코드
이지 랜덤을 이용한 객체 생성 로직은 똑같으므로 생략하도록 한다.
BulkInsertTest
// #2 JPA - saveAll()
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<Post> posts = IntStream.range(0, 1000)
.mapToObj(i -> easyRandom.nextObject(Post.class))
.toList();
stopWatch.stop();
System.out.println("객체 생성 시간: " + stopWatch.getTotalTimeSeconds());
StopWatch queryStopWatch = new StopWatch();
queryStopWatch.start();
postRepository.saveAll(posts);
queryStopWatch.stop();
System.out.println("DB Insert 시간: " + queryStopWatch.getTotalTimeSeconds());2-2. 결과
생성 로직이 똑같기 때문에 객체 생성 시간은 모든 테스트에서 거의 똑같을 것이다.
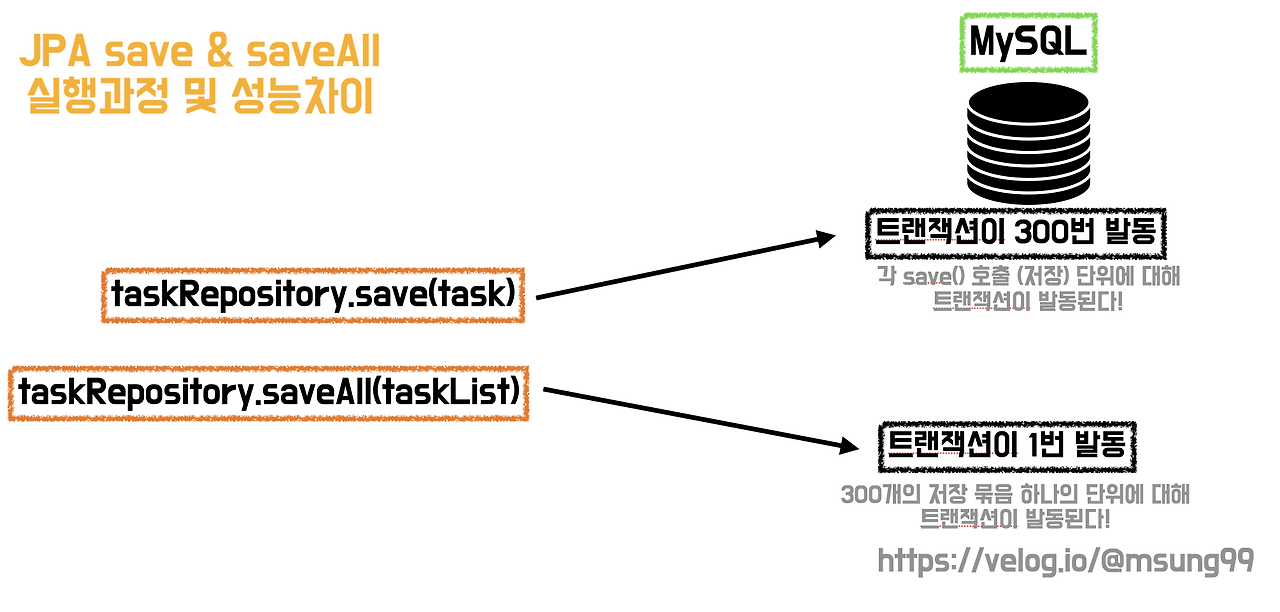
그런데 DB Insert 시간에서 save()와 큰 차이가 난다.
아무래도 트랜잭션을 1000번 열고 닫는 save() 보다는 1번 열고 닫는 saveAll()이 효율이 더 좋다.
하지만 save()와 마찬가지로 DB에 Insert 쿼리를 1000번 날리고 있다는 문제가 있다.


3. JPA - Bulk Insert
위처럼 2초 정도면 그래도 괜찮지 않나..? 하는 생각도 들지만 좀 더 나아가보자.
이제 성능 개선을 위해서는 한번의 Insert 쿼리로 1000건의 데이터를 넣을 수 있는 Bulk Insert에 눈이 간다.
만약 ID 생성 전략이 Auto Increment가 아니고, Jpa의 Bulk Insert 기능을 사용하고자 한다면 아래처럼 yml 설정을 해주면 된다.
본인은 Auto Increment 전략을 사용하고 있으므로 Jpa의 Bulk Insert 테스트는 생략하도록 하겠다.
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 100
order_inserts: true # 삽입 작업 최적화
order_upates: true # 업데이트 작업 최적화4. JDBC - Bulk Insert
본인의 프로젝트의 ID 생성 전략이 Auto Increment이므로 하이버네이트의 Bulk Insert 기능을 사용할 수 없다.
그래서 Bulk Insert를 사용하기 위해 JDBC Template을 사용하는 Repository를 따로 만들었다.
4-1. 코드
PostJdbcRepository
NamedParameterJdbcTemplate 를 사용하였다.
@Repository
@RequiredArgsConstructor
public class PostJdbcRepository {
private static final String TABLE = "post";
private final NamedParameterJdbcTemplate jdbcTemplate;
public void bulkInsert(List<Post> postList) {
String sql = String.format("""
INSERT INTO %s (member_id, content, created_date)
VALUES (:memberId, :content, :createdDate)
""", TABLE);
SqlParameterSource[] params = postList.stream()
.map(BeanPropertySqlParameterSource::new)
.toArray(SqlParameterSource[]::new);
jdbcTemplate.batchUpdate(sql, params);
}
}BulkInsertTest
// #3 JdbcTemplate - bulk insert
StopWatch stopWatch = new StopWatch();
stopWatch.start();
List<Post> posts = IntStream.range(0, 10000 * 10)
.mapToObj(i -> easyRandom.nextObject(Post.class))
.toList();
stopWatch.stop();
System.out.println("객체 생성 시간: " + stopWatch.getTotalTimeSeconds());
StopWatch queryStopWatch = new StopWatch();
queryStopWatch.start();
postJdbcRepository.bulkInsert(posts);
queryStopWatch.stop();
System.out.println("DB Insert 시간: " + queryStopWatch.getTotalTimeSeconds());4-2. 결과
객체 생성 로직은 똑같으므로 위 테스트들과 거의 똑같은 시간이 걸린다.
하지만 DB Insert 시간이 극적으로 차이가 난다.


아래처럼 쿼리 단 한번으로 모든 데이터를 삽입하니 훨씬 적은 시간이 드는걸 알 수 있다.
또한 JPA는 엔티티를 영속화 하면 1차 캐시에 저장하고 관리하므로 오버헤드가 더 생길 것이다.
따라서 이렇게 큰 차이가 생긴다고 생각할 수 있다.

5. 정리
정리하자면 1000건의 데이터 Insert에 대한 결과는 아래와 같다.
5-1. JPA - save() 1000건
5-2. JPA - saveAll() 1000건
5-3. JDBC - Bulk Insert 1000건
save() vs saveAll() 에서는 트랜잭션 수 의 차이가 있었고
saveAll() vs Bulk Insert 에서는 Insert 쿼리 수 의 차이가 있었다.
또한 JPA는 엔티티를 영속화 하면 1차 캐시에 저장하고 관리하므로 오버헤드가 더 생긴다.
이상이 DB Insert 시간에 차이가 생기는 원인이라고 생각할 수 있다.
위 결과는 1000건의 데이터에 대한 결과지만, 데이터 건수가 늘어날수록 차이는 훨씬 벌어진다.
Jpa가 DB를 굉장히 편하게 사용할 수 있게 해주지만, 어느 정도 한계는 있는듯 하다.
물론 하이버네이트가 지원하는 Bulk Insert를 사용할 수 있다면 괜찮겠지만 Auto Increment 일땐 사용할 수 없으니...
아무래도 은총알은 없다는 말처럼, Jpa에 국한되지 말고 필요할때 적절한 기술을 사용해야할것 같다.
'백엔드 > Spring Data' 카테고리의 다른 글
| DB에 100만 건의 데이터 삽입 해보기 (0) | 2024.05.26 |
|---|---|
| DB에 여러 건의 데이터를 넣는 방법 (0) | 2024.04.23 |
| 스프링부트 실행 시 데이터 넣어두기 - Data.sql (2) | 2023.10.01 |